Regression discontinuity
Regression discontinuity design (RDD)
Remember the example from class about the effect of being in a gifted program on future earnings. The DAG looks like this:
library(ggdag)
library(tidyverse)
# dag
dagify(earnings ~ gifted + ability,
gifted ~ ability,
exposure = "gifted",
outcome = "earnings") %>%
ggdag_status(text = FALSE, use_labels = "name") + theme_dag() +
theme(legend.position = "none")
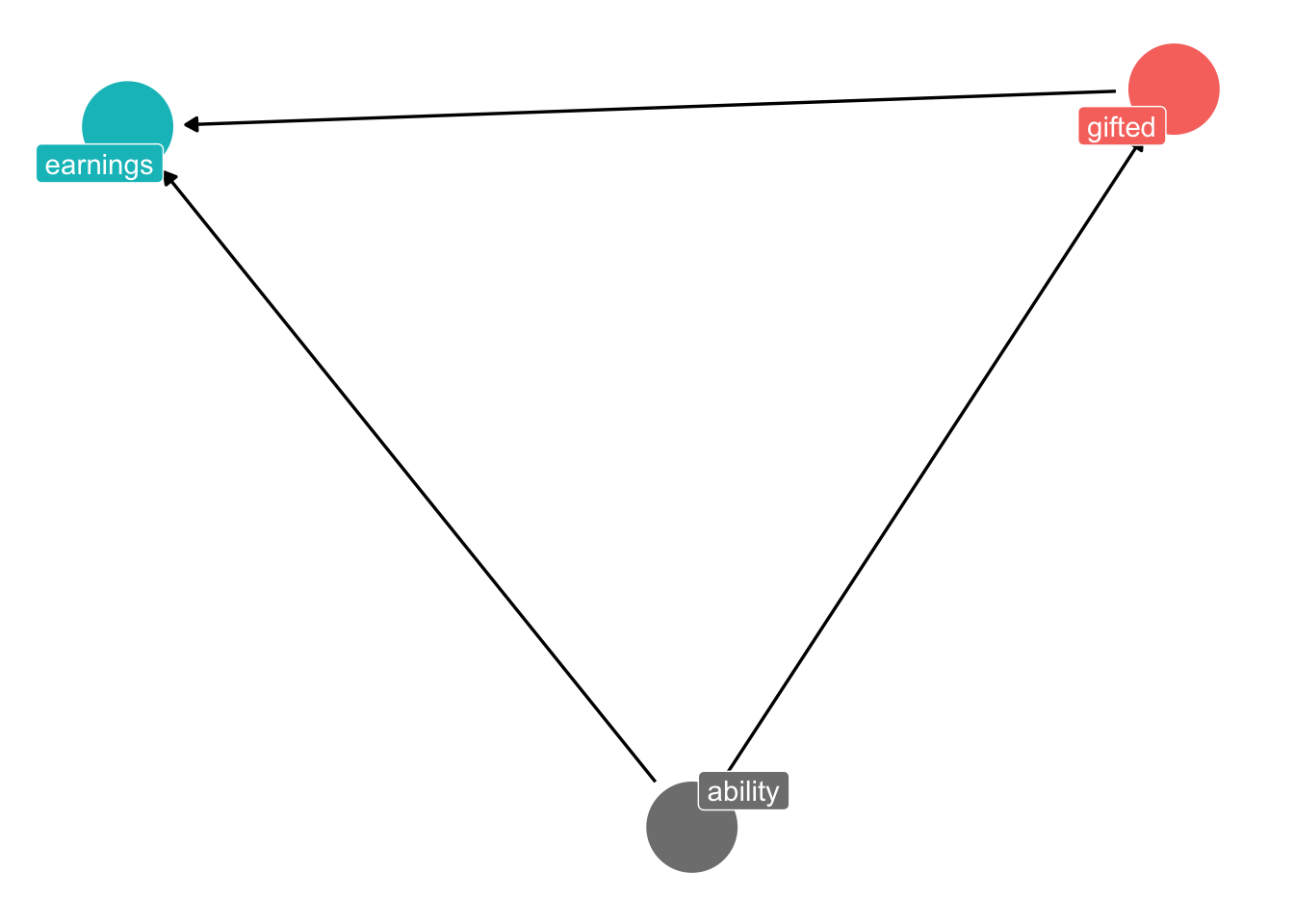
The problem is that students aren’t randomly placed in gifted programs; they are put there for a host of reasons (including, for instance, “ability”).
The idea behind the RDD is to exploit the fact that the exact test score that gets you into gifted is arbitrary, while the test itself is noisy. This means that students just below and above that cutoff score (75) are pretty similar, but some just barely made it and others just barely didn’t (for reasons that are arguably random: luck, mostly).
That phrase is key: “for reasons that are arguably random…”. Some students got treatment and others got the control condition randomly, i.e., an experiment.
Make up data to see how it works:
set.seed(1991)
# discontinuity example
fake = tibble(kids = 1:1000,
test = runif(1000)*100) %>%
mutate(gifted = ifelse(test >= 75, 1, 0)) %>%
mutate(earnings = runif(1000)*40 + 10*gifted + .5*test)
ggplot(fake, aes(x = test, y = earnings)) +
geom_point()
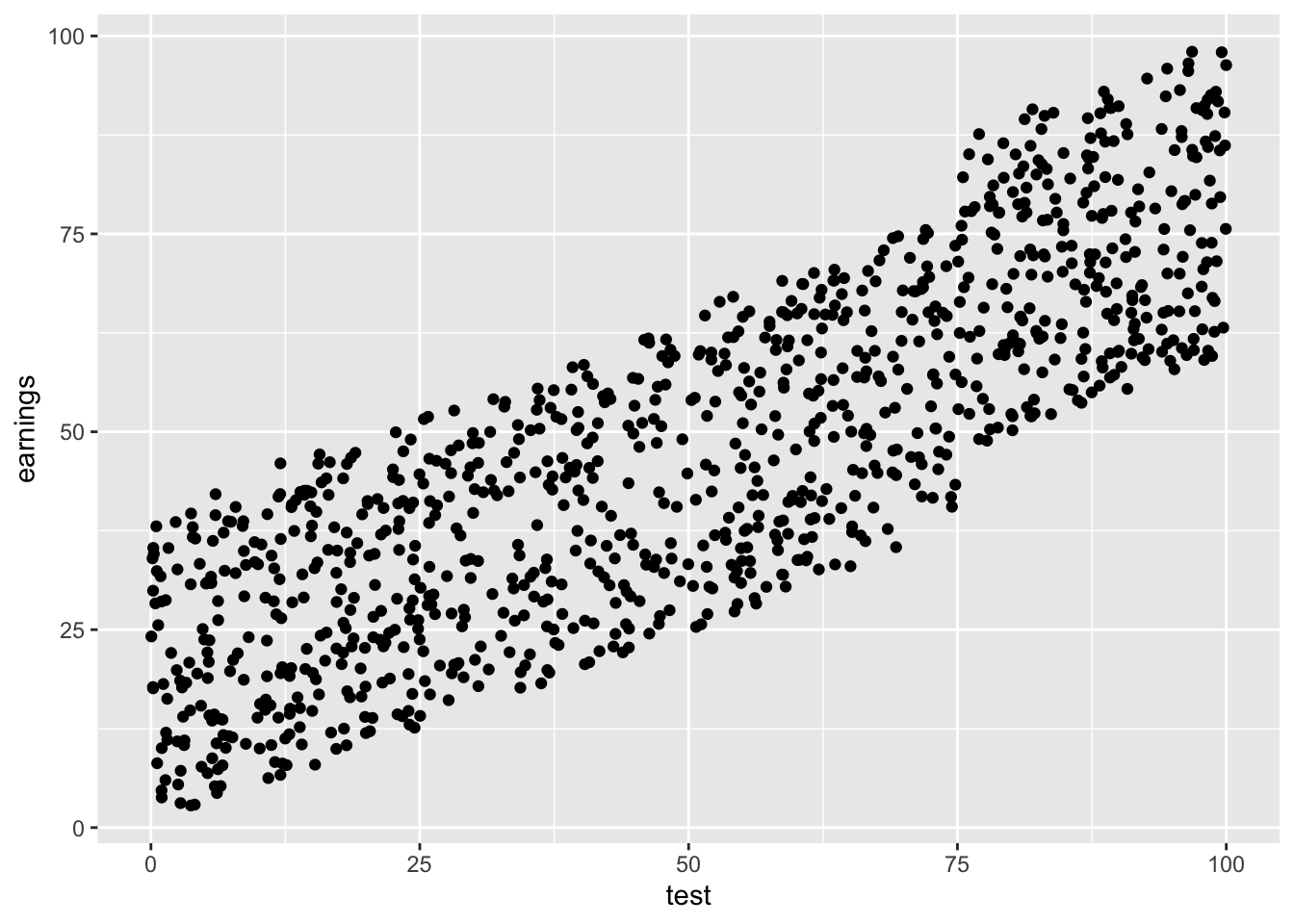
Do it by hand:
# rdd by hand
fake %>%
filter(test >= 73, test <= 77) %>%
group_by(gifted) %>%
summarise(earnings = mean(earnings))
## # A tibble: 2 × 2
## gifted earnings
## <dbl> <dbl>
## 1 0 54.7
## 2 1 68.2